
Nakon pregleda načina na koji funkcioniraju baze dokumenata i razlika u odnosu na dominantan model relacijskih baza podataka, slijedi opis ostala tri modela baza podataka.
- Document Databases
- Graph Databases
- Columnar Databases
- In-Memory Data Grids
Graph Databases
Ovaj oblik baza podataka temelji se na teoriji grafova, a ključni pojmovi kojima se rukuje tijekom rada s podacima su: čvorovi i svojstva (nodes i properties). Takav oblik strukture podataka pogodan je, prije svega, za uspostavljanje vrlo složenih veza među podacima kakve se pojavljuju u modernom poslovnom okruženju (i izvan njega).
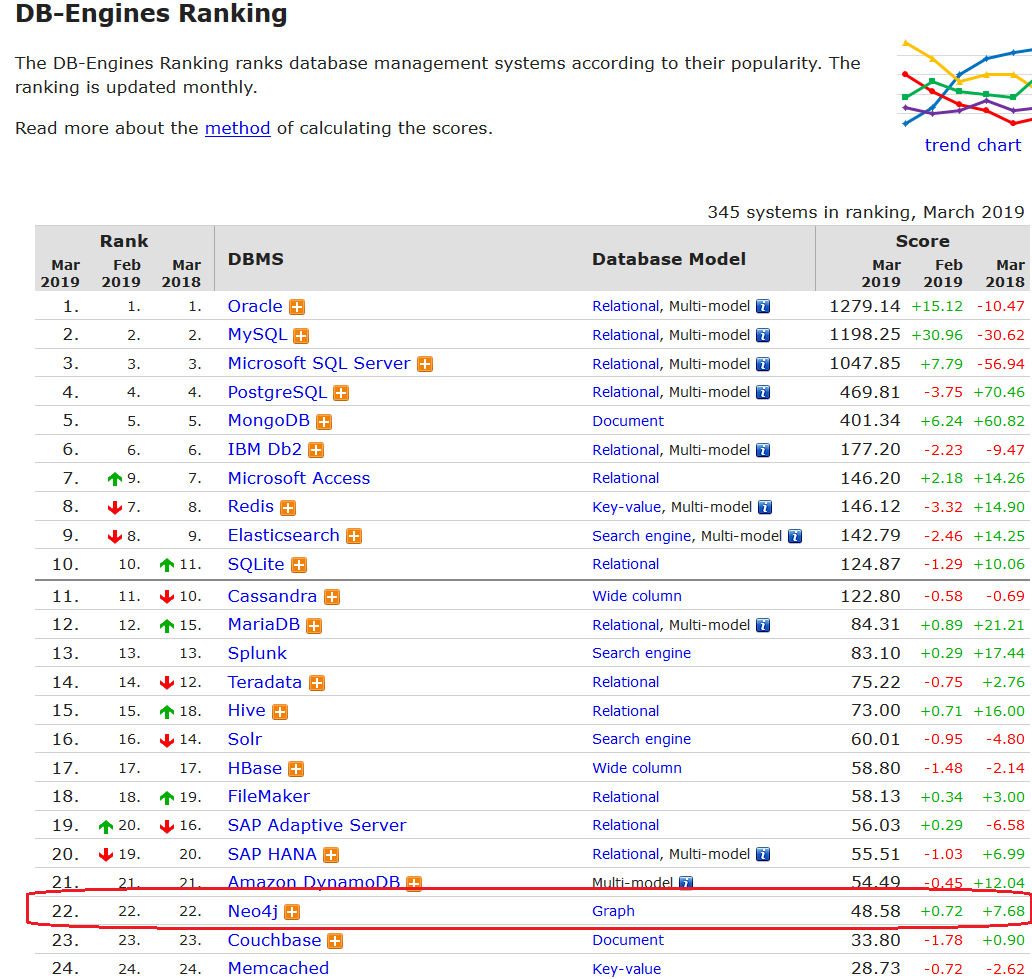
Kao primjer sustava za upravljanje bazom podataka iz ove grupe navest ćemo Neo4j. Riječ je o proizvodu istoimene tvrtke Neo4j, Inc., čija se prva verzija pojavila tek 2010. godine. Trenutačno je Neo4j najpopularnija baza podataka takvog tipa, a među svim vrstama baza podataka Neo4j je (u trenutačnoj verziji 3.5.3) na 22 mjestu s tendencijom konstantnog povećanja popularnosti.
Kao i veliki broj drugih, danas popularnih baza podataka, dostupna je u dvije verzije – komercijalnoj i besplatnoj – takozvana verzija Community Edition. Najveća razlika između ovih verzija je u dodatnim modulima koji omogućavaju upotrebu klaster konfiguracija servera, nadzor nad radom baze podataka i hot backup.
U nastavku je demonstrirano korištenje bazom podataka Neo4j pomoću programskog jezika PHP na području koje u praksi zahtijeva puno međusobnih veza između čvorova – podaci o filmovima i glumcima. U jednom filmu može glumiti veliki broj glumaca, a vrijedi i suprotna veza – jedan glumac može biti uključen u veliki broj filmova.
Primjer spremanja podataka u bazu pomoću stvaranja čvorova o glumcima i filmovima:
$keanu = new Node($client);
$keanu->setProperty('name', 'Keanu Reeves')->save();
$laurence = new Node($client);
$laurence->setProperty('name', 'Laurence Fishburne')->save();
$jennifer = new Node($client);
$jennifer->setProperty('name', 'Jennifer Connelly')->save();
$kevin = new Node($client);
$kevin->setProperty('name', 'Kevin Bacon')->save();
$matrix = new Node($client);
$matrix->setProperty('title', 'The Matrix')->save();
$higherLearning = new Node($client);
$higherLearning->setProperty('title', 'Higher Learning')->save();
$mysticRiver = new Node($client);
$mysticRiver->setProperty('title', 'Mystic River')->save();
Slika 1. Trenutačna popularnost baze podataka Neo4j
U slučaju da treba napraviti dodatno povezivanje postojećih podataka o glumcima i filmovima, primjer bi mogao imati sljedeći oblik:
$keanu->relateTo($matrix, 'IN')->save();
$laurence->relateTo($matrix, 'IN')->save();
$laurence->relateTo($higherLearning, 'IN')->save();
$jennifer->relateTo($higherLearning, 'IN')->save();
$laurence->relateTo($mysticRiver, 'IN')->save();
$kevin->relateTo($mysticRiver, 'IN')->save();
Za pronalaženje postojećih veza među podacima u bazi podataka može se koristiti sljedeći oblik:
$path = $keanu->findPathsTo($kevin)
->setMaxDepth(12)
->getSinglePath();
foreach ($path as $i => $node) {
if ($i % 2 == 0) {
echo $node->getProperty('name');
if ($i+1 != count($path)) {
echo " was in\n";
}
} else {
echo "\t" . $node->getProperty('title') . " with\n";
}
}
Columnar Databases
Kod ovog tipa baze podataka naglasak je na brzini pristupa podacima, jer u današnjim sustavima s ogromnom količinom podataka brzina pristupa podacima predstavlja sve veći problem. Za sam pristup podacima i dalje se u pravilu može koristiti SQL kao jezik upita, što je svakako jedna od važnih prednosti, jer ne treba učiti potpuno nov jezik kao preduvjet za korištenje baze podataka.
Način na koji ovakva organizacija podataka ubrzava pristup podacima, u odnosu na standardni relacijski model, najjednostavnije je objasniti na primjeru. Na ukupnu brzinu pristupa podacima u najvećoj mjeri utječe upravo njihova organizacija na diskovima (zbog sporosti diskova u odnosu na druge komponente računala). Pretpostavimo da treba spremiti sljedeće podatke:
| EmpID | Lastname | Firstname | Salary |
| 10 | Smith | Joe | 40000 |
| 12 | Jones | Mary | 50000 |
| 11 | Jonson | Cathy | 44000 |
| 22 | Jones | Bob | 55000 |
Kod relacijskog modela baza podataka prethodni podaci spremaju se na disk slijedno u obliku:
001:10,Smith,Joe,40000;002:12,Jones,Mary,50000;003:11,Johnson,Cathy,44000;004:22,Jones,Bob,55000;
U slučaju da su istovremeno potrebni svi podaci iz jednog sloga, onda je takvo spremanje podataka optimalno u smislu brzine pristupa. Međutim, praksa pokazuje da je vrlo često iz jednog ili više slogova potrebno uzeti samo dio podataka, na primjer, podatke EmpID i Salary. Što je veća ukupna veličina sloga u nekoj tablici, to je češći slučaj da se tijekom pristupa podacima koristi samo jedan dio sloga.
Kako bi se ubrzalo pretraživanje i dohvaćanje podataka, u relacijskom modelu osnovnim tablicama s podacima dodaju se indeksi (za dodatne detalje o organizaciji i indeksima možete pročitati tekst istog autora objavljen ranije na ovom portalu). Za prije opisani slučaj indeks bi mogao imati sljedeći sadržaj:
001:40000;002:50000;003:44000;004:55000;
Budući da su indeksi znatno manji od cijelog sadržaja tablica, pretraživanje je znatno djelotvornije i brže. Upotreba indeksa ima i svoju lošu stranu, a to je konstantno održavanje njihovog sadržaja. Ako se za složenu tablicu pripremi veći broj indeksa (kako bi se ubrzalo pretraživanje) time se automatski usporava unos/ažuriranje/brisanje slogova, jer kod svake takve operacije treba ažurirati sadržaj svih relevantnih indeksa.
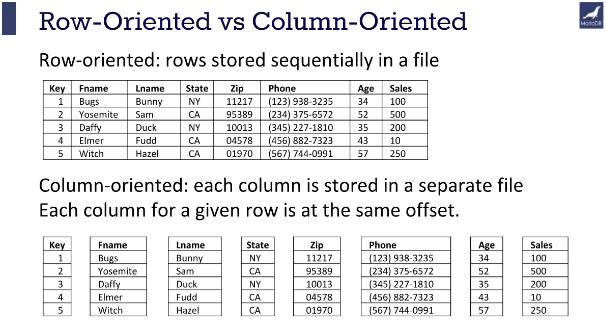
Kod baza podataka orijentiranih prema kolonama, podaci se na disku spremaju u sasvim drugačijem redoslijedu u datoteku na disku (ili čak kao više odvojenih datoteka):
10:001,12:002,11:003,22:004;Smith:001,Jones:002,Johnson:003,Jones:004;Joe:001,Mary:002,
Cathy:003,Bob:004;40000:001,50000:002,44000:003,55000:004;
Podaci u ovom modelu zapravo izgledaju kao veći broj indeksa iz relacijskog modela navedenih jedan za drugim. U slučaju ponavljanja istog podatka (npr. imena Jones u prethodnom primjeru) čak je moguće samo nabrojiti sva mjesta na kojima se pojavljuje takav podatak, umjesto višestrukog zapisivanja istog podatka. Time se automatski postiže kompresija spremljenih podataka. Na primjer:
…;Smith:001,Jones:002,004,Johnson:003;…
Kao posljedica navedenih promjena, operacije čitanja podataka mnogo su brže nego kod klasičnog relacijskog modela, jer se u većini slučajeva čitaju samo točno određeni podaci. Također, kod ažuriranja podataka nema potrebe za gubljenjem vremena na održavanje brojnih indeksa kao u relacijskom modelu.
Slika 2. Usporedba različitog načina spremanja podataka
Primjer komercijalnog sustava temeljenog na opisanim principima je Amazon Redshift. Osim velike brzine pretraživanja podataka u realnom svijetu, sustav nudi različite razvojne i BI alate za rad s podacima spremljene u bazu.
Što se tiče jezika pristupa podacima, na raspolaganju su brojne dobro poznate mogućnosti iz standardnog jezika upita SQL, ali je zato dio DDL parametara, uobičajen kod definiranja tablica u relacijskom modelu, postao nepotreban (npr. brojni parametri za podešavanje fizičke organizacije podataka na disku u DDL SQL CREATE TABLE naredbi).
In-Memory Data Grids
Jedan od najjednostavnijih načina ubrzavanja rada baza podataka je čuvanje dijela baze podataka (ili čitave baze) u radnoj memoriji računala umjesto na puno sporijim diskovima. Veći broj proizvođača baza podataka, bez obzira na njihovu internu organizaciju, danas nudi takvu mogućnost rukovanja podacima. Kod relacijski orijentirane baze podataka dio podataka (ili svi podaci) može se stalno nalaziti u radnoj memoriji računala, ali po svojim karakteristikama to i dalje ostaje standardni relacijski model baze podataka.
Posebna vrsta baza podataka (In-Memory Data Grids) ne predstavlja samo obično preslikavanje podataka s diskova u memoriju računala, nego različitim izmjenama u samoj organizaciji podataka nudi dodatno povećanje performansi u radu. Umjesto čuvanja podataka u obliku slogova ili kolona (kao u prije objašnjenim modelima baza podataka) u ovom modelu podaci se obično čuvaju kao kombinacija vrijednosti ključeva i samih vrijednosti (key/value parovi).
Navedene promjene dovode do ograničavanja nekih od standardnih mogućnosti relacijskih baza podataka (na primjer, dijela mogućnosti SQL upita ili indeksiranja), ali istovremeno nude brojne prednosti za sustave s izrazito velikim brojem procesora (velika brzina izvođenja upita te jednostavna mogućnost uključivanja dodatnih hardverskih resursa u sustav).
Kao primjer proizvoda zasnovanog na principima In-Memory Data Grids možemo navesti ScaleOut StateServer. Jedna od ključnih karakteristika i prednosti ove baze podataka je jednostavno uključivanje dodatnih servera u sustav kad se za tim ukaže potreba.
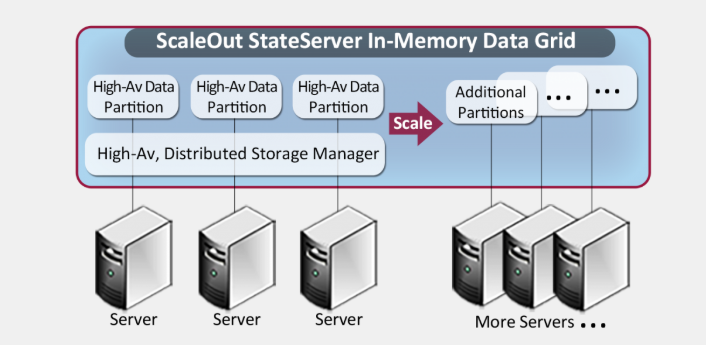
Slika 3. Uključivanje novih hardverskih resursa u ScaleOut StateServer
ScaleOut StateServer preko API-ja omogućava izravno korištenje u programskim jezicima Java, .NET i C/C++, a pomoću ugrađene podrške REST API također u većini drugih programskih jezika. Iako većina aplikacija zahtijeva pojedinačne vrijednosti iz baze podataka tijekom izvođenja jednog upita, sustavi In-Memory Data Grids pogodni su za implementaciju paralelnog izvođenja upita na svim raspoloživim hardverskim resursima (serverima). Ponovo preko odgovarajućih API-a poziva optimiziranih za paralelne arhitekture računala ScaleOut StateServer nudi izravno korištenje upita s paralelnim izvođenjem u ranije spomenutim programskim jezicima Java, .NET i C/C++.
Alternativne organizacije baza podataka u pojedinim slučajevima nude brojne prednosti u odnosu na standardni relacijski model. Međutim, to ne znači da će relacijski model odjednom nestati i ustupiti mjesto drugim modelima, prije svega zbog brojnih unapređenja koje proizvođači posljednjih godina dodaju u svoje relacijski orijentirane baze podataka.