
U prethodna dva teksta objašnjene su najvažnije razlike između relacijskog modela baze podataka i nekoliko najpopularnijih alternativnih modela. Iako u određenim situacijama alternativni modeli imaju prednosti u odnosu na relacijski model, to ne znači da će relacijske baze podataka odjednom nestati iz upotrebe. Ako ni zbog čega drugog, onda zato što se u sustavima temeljenim na takvoj organizaciji baza podataka već čuva ogromna količina podataka, a brojna aplikativna rješenja pripremljena su isključivo za upotrebu takvih izvora podataka. Potpuni prelazak na alternativne modele tražio bi ogromne resurse (tehničke, ljudske i financijske), što u praksi najčešće nije izvedivo.
Zato proizvođači relacijskih baza podataka posljednjih godina u svoje proizvode dodaju različita proširenja standardnog relacijskog modela kako bi se omogućilo njihovo korištenje u drugačijim uvjetima nestrukturiranih podataka. U nastavku teksta prikazano je nekoliko različitih pristupa rješavanju problema.
MariaDB ColumnStore
MariaDB, kao trenutačno jedan od najpopularnijih relacijski orijentiranih sustava za upravljanje bazama podataka (razvijen od strane istih autora kao i MySQL), dozvoljava upotrebu različitih modula za pristup podacima zapisanim na disku na najnižoj razini sustava (Storage Engine). Osim podrazumijevanih modula opće namjene (XtraDB do verzije 10.1) te (InnoDB od verzije 10.2), MariaDB za pristup podacima podržava upotrebu različitih dodatnih modula.
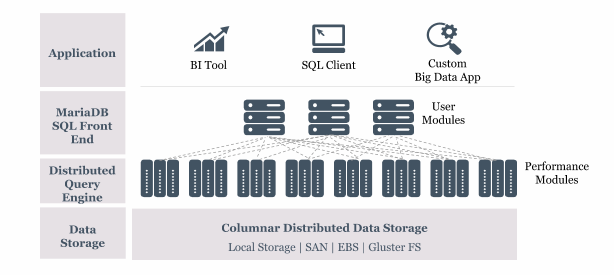
Slika 1. Sistemski modul ColumnStore u bazi podataka MariaDB
Jedan od takvih modula je MariaDB ColumnStore koji omogućava zamjenu relacijski orijentirane organizacije zapisa podataka na disku u zapise orijentirane prema kolonama (detaljno objašnjeno u prethodnom članku). Modul MariaDB ColumnStore i dalje podržava postojeću SQL sintaksu, ali je pogodnji za rad s vrlo velikim količinama podataka. U istom upitu čak je moguće međusobno povezivati tablice s različitom organizacijom podataka –relacijski organizirane tablice te tablice orijentirane prema kolonama.
Ovakav pristup pokazuje jedan od mogućih načina na koji proizvođači relacijskih baza podataka mogu unaprijediti klasičan relacijski model – uključivanjem podrške za druge oblike organizacije podataka uz zadržavanje svih prednosti osnovnog relacijskog modela.
Tip podataka JSON
Jedan od načina na koji se relacijski orijentirane baze podataka mogu proširiti tako da podržavaju nestrukturirane vrste podataka je upotreba dobro poznatog JSON (JavaScript Object Notation) oblika zapisa podataka.
Primjer JSON podataka:
{"menu": {
"id": "file",
"value": "File",
"popup": {
"menuitem": [
{"value": "New", "onclick": "CreateNewDoc()"},
{"value": "Open", "onclick": "OpenDoc()"},
{"value": "Close", "onclick": "CloseDoc()"}
]
}
}}
Budući da JSON podaci zapravo predstavljaju posebno organiziranu vrstu tekstualnih podataka, u bazi podataka mogu se čuvati u uobičajenim tablicama kao poseban stupac. Na primjer, u Microsoftovom SQL Serveru to je stupac tipa nvarchar(max). To ujedno znači kako su za JSON zapis u tablici dostupne sve standardne mogućnosti za tekstualno orijetirane tipove podataka (indeksi, funkcije i slično).
U pogledu načina rukovanja JSON podacima, moguća su dva pristupa:
- Jednostavniji – cjelokupna obrada JSON zapisa izvodi se u aplikaciji koja se njima koristi, dok je s gledišta baze podataka riječ o običnom tekstualnom podatku.
- Napredniji – baza podataka „poznaje“ tip podatka JSON te ga izravno podržava dodatnim proširenjima u jeziku upita SQL, što povećava performanse u odnosu na prvi pristup.
Novije verzije SQL Servera imaju ugrađena brojna proširenja za JSON tip podataka, pa je moguće u istom SQL upitu kombinirati dijelove za pristup standardnim relacijski orijentiranim podacima i JSON zapisima. Slijedi primjer takvog upita za SQL Server:
SELECT Name,Surname,
JSON_VALUE(jsonCol,'$.info.address.PostCode') AS PostCode,
JSON_VALUE(jsonCol,'$.info.address."Address Line 1"')+' '
+JSON_VALUE(jsonCol,'$.info.address."Address Line 2"') AS Address,
JSON_QUERY(jsonCol,'$.info.skills') AS Skills
FROM People
WHERE ISJSON(jsonCol)>0
AND Status='Active'
ORDER BY JSON_VALUE(jsonCol,'$.info.address.PostCode')
Dio podataka u prethodnom upitu (npr. Name, Surname) predstavljaju stupci tablice, dok se drugi dio podataka dobiva iz vrijednosti JSON podatka spremljenog u stupac jsonCol. U konkretnom slučaju iz prethodnog primjera dodavanjem JSON podatka u standardnu relacijsku tablicu može se postići velika fleksibilnost zapisa adresa za svaku pojedinu osobu.
Na sličan način podržane su druge neophodne operacije na JSON podacima, kao, na primjer, njihovo ažuriranje:
DECLARE @json NVARCHAR(MAX);
SET @json = '{"info":{"address":[{"town":"Amsterdam"},{"town":"Paris"},{"town":"Madrid"}]}}';
SET @json = JSON_MODIFY(@json,'$.info.address[1].town','London');
SELECT modifiedJson = @json;
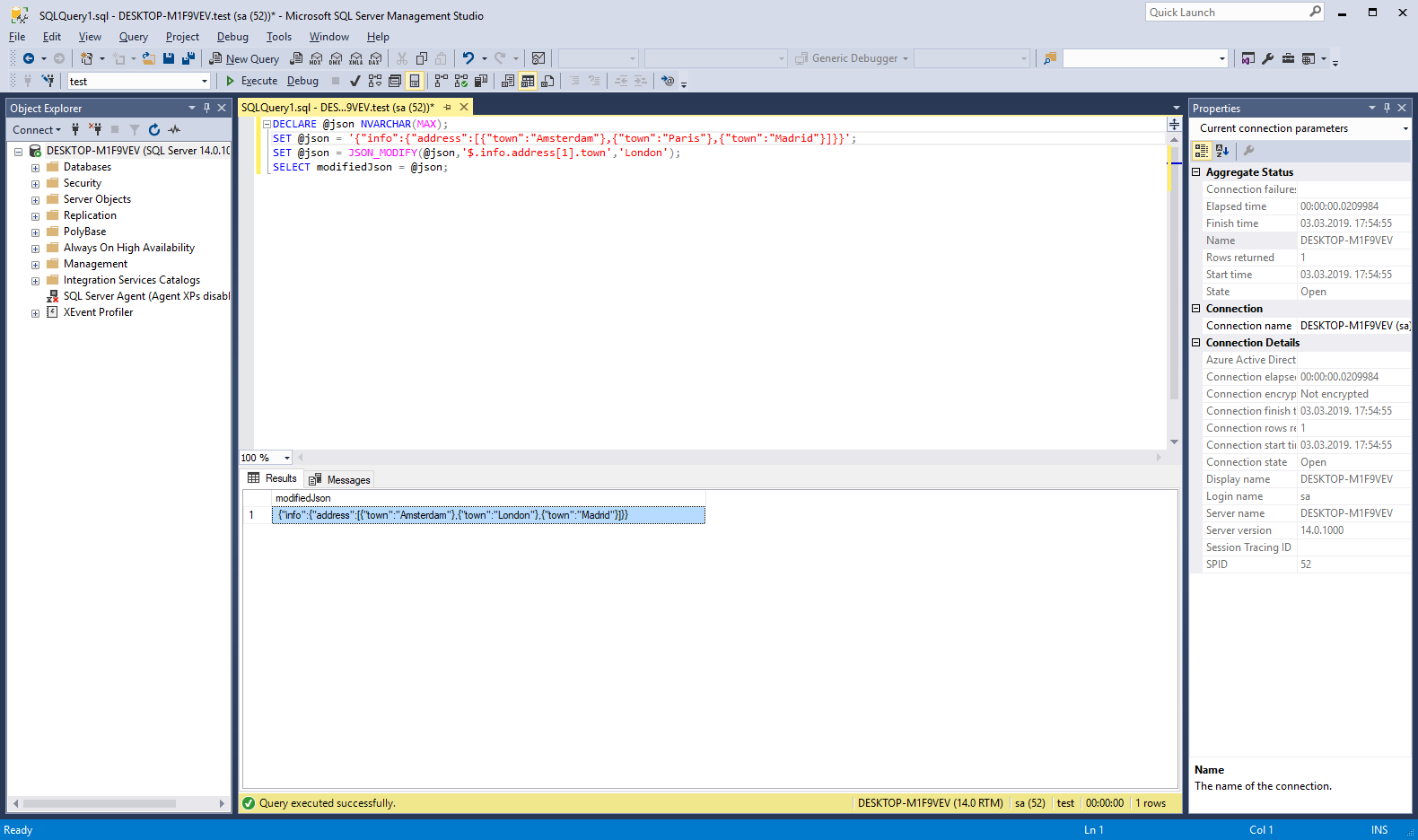
Slika 2. Primjer ažuriranja JSON podataka u SQL Serveru
Tip podataka XML
Drugi način na koji se u relacijski orijentiranim bazama podataka može raditi s nestrukturiranim podacima je upotreba posebnog tipa podataka XML (XML – Extensible Markup Language). Početni primjer JSON podatkaiz prethodnog poglavlja, u XML-u ima sljedeći oblik:
<menu id="file" value="File">
<popup>
<menuitem value="New" onclick="CreateNewDoc()" />
<menuitem value="Open" onclick="OpenDoc()" />
<menuitem value="Close" onclick="CloseDoc()" />
</popup>
</menu>
U Microsoftovom SQL Serveru podrška za tip podatka XML implementirana je nešto drugačije nego za JSON. Umjesto standardnog tekstualnog tipa podatka uvedena je posebna vrsta podataka XML, za koju su također dodana potrebna proširenja u osnovni SQL jezik.
Slijedi primjer pripreme tablice s XML tipom podataka te učitavanje početnih vrijednosti u tablicu iz vanjske tekstualne datoteke:
DROP TABLE IF EXISTS XMLwithOpenXML
go
CREATE TABLE XMLwithOpenXML
(
Id INT IDENTITY PRIMARY KEY,
XMLData XML,
LoadedDateTime DATETIME
)
INSERT INTO XMLwithOpenXML(XMLData, LoadedDateTime)
SELECT CONVERT(XML, BulkColumn) AS BulkColumn, GETDATE()
FROM OPENROWSET(BULK 'C:\Tmp2\test.xml', SINGLE_BLOB) AS x;
U tekstualnoj datoteci, odakle se učitavaju početne vrijednosti trebaju se nalaziti odgovarajuće formatirani XML podaci. Na primjer:
<ROOT>
<Customers>
<Customer CustomerID="001" CustomerName="Nenad Crnko">
<Orders>
<Order OrderID="1001" OrderDate="2019-03-01T00:00:00">
<OrderDetail ProductID="101" Quantity="5" />
<OrderDetail ProductID="110" Quantity="12" />
</Order>
</Orders>
<Address> Address line 1, 2, 3</Address>
</Customer>
...
</ROOT>
Nakon učitavanja podataka njihov pregled može se napraviti standardnom naredbom SQL Select kao što je to napravljeno na sljedećoj slici.
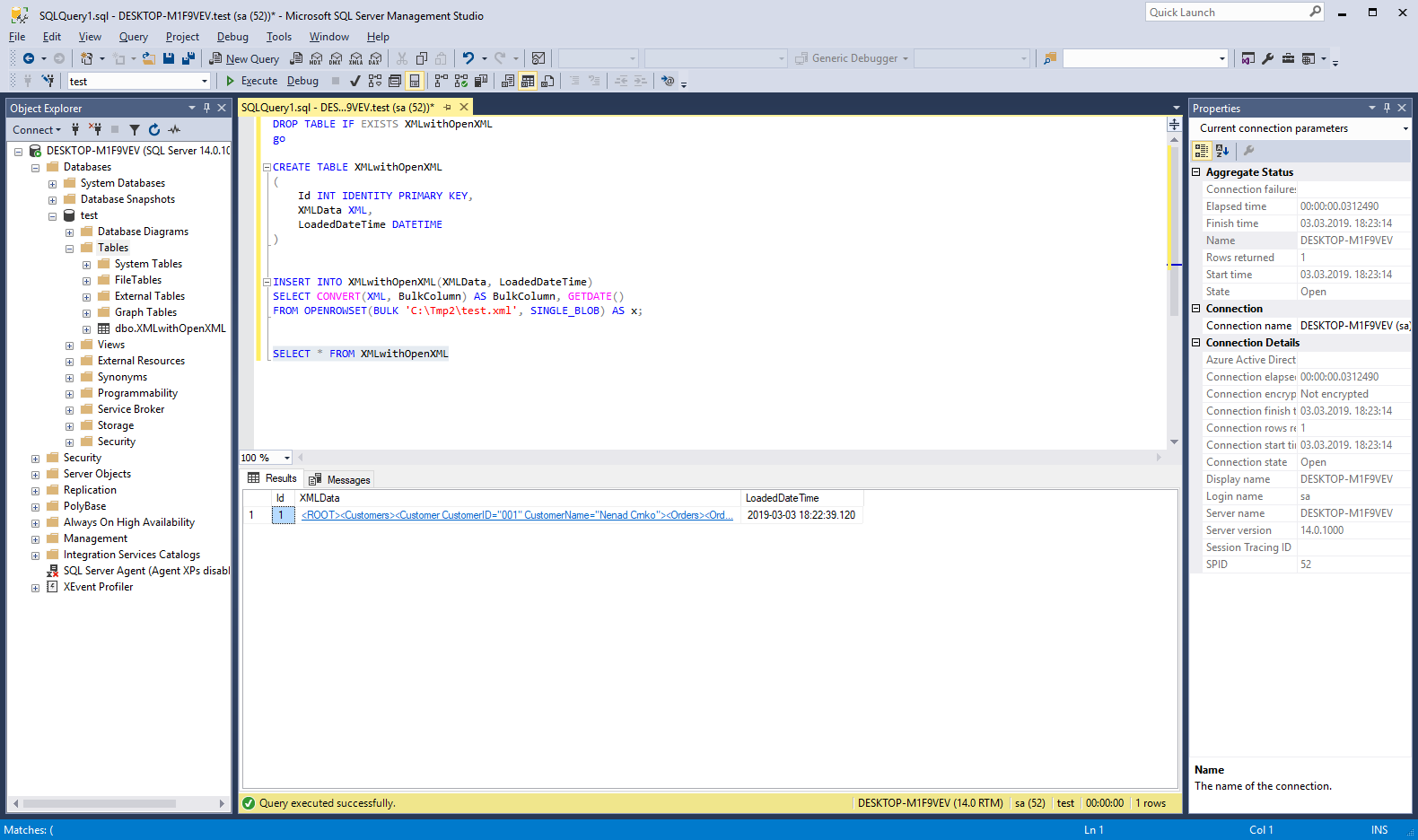
Slika 3. Priprema, punjenje i pregled tablice s XML tipom podatka.
Po potrebi se podaci spremljeni u XML stupcu mogu pretvoriti u tablicu, kao što to pokazuje sljedeći primjer:
DECLARE @XML AS XML, @hDoc AS INT, @SQL NVARCHAR (MAX)
SELECT @XML = XMLData FROM XMLwithOpenXML
EXEC sp_xml_preparedocument @hDoc OUTPUT, @XML
SELECT top 2 CustomerID, CustomerName, Address, OrderID, OrderDate, ProductID, Quantity
FROM OPENXML(@hDoc, 'ROOT/Customers/Customer/Orders/Order/OrderDetail')
WITH
(
CustomerID [varchar](50) '../../../@CustomerID',
CustomerName [varchar](100) '../../../@CustomerName',
Address [varchar](100) '../../../Address',
OrderID [varchar](1000) '../@OrderID',
OrderDate datetime '../@OrderDate',
ProductID [varchar](50) '@ProductID',
Quantity int '@Quantity'
)
EXEC sp_xml_removedocument @hDoc
GO
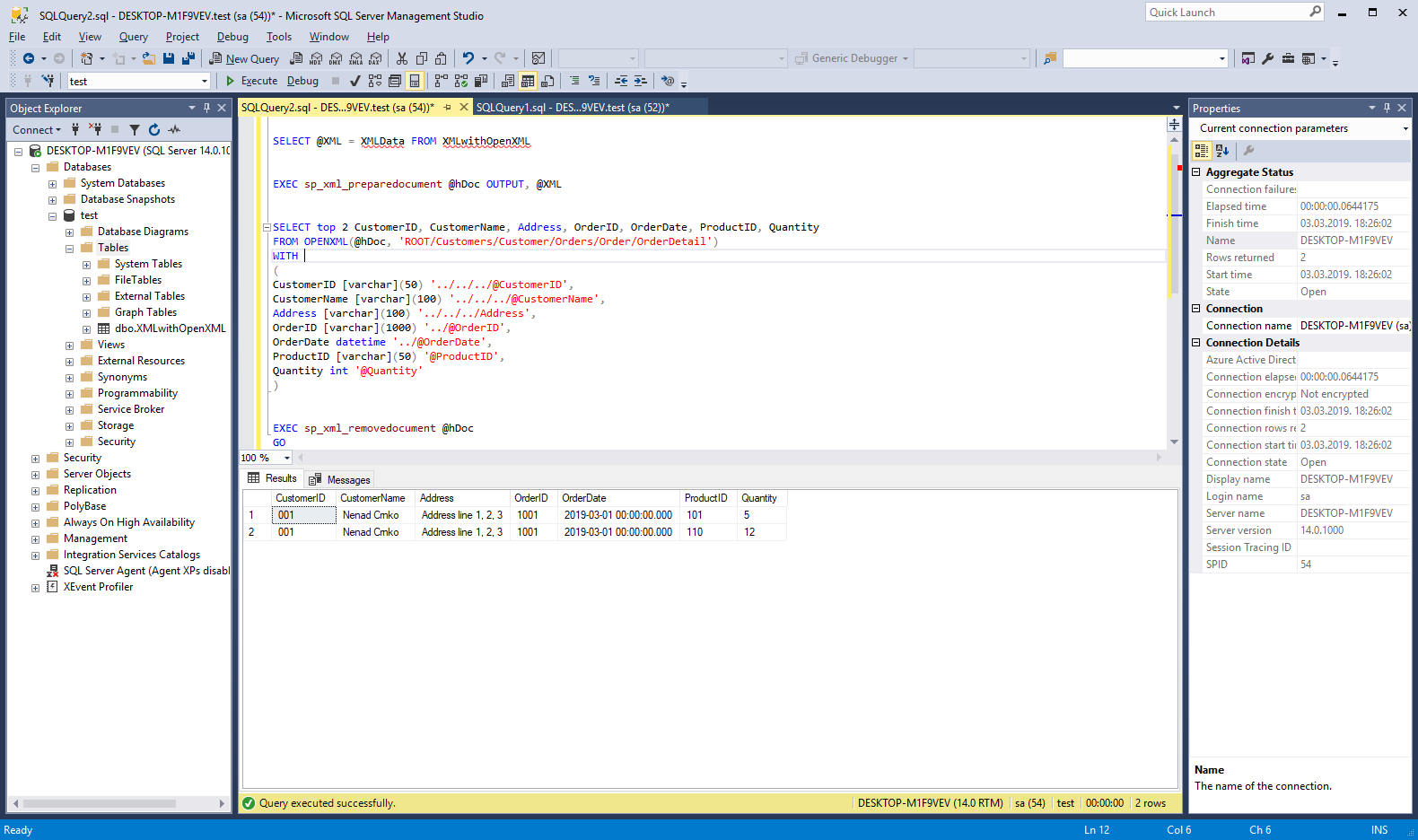
Slika 4. Pretvaranje XML podataka u tablicu
Upotrebom JSON i XML tipova podataka, odnosno drugačijih modula za pristup zapisanim podacima na disku (ako to dozvoljava sustav za upravljanje bazom podataka kao MariaDB), moguće je proširiti postojeće relacijske modele baza podataka tako da podržavaju drugačiju organizaciju i tipove podataka. Glavna prednost takvog pristupa je da se i dalje mogu upotrebljavati postojeće aplikacije napisane za relacijske baze podataka, a u razvoju dodatnih funkcionalnosti mogu se upotrebljavati drugačije (nestrukturirane) vrste podataka.