
Brzo pretraživanje relacijskih baza podataka temelji se na korištenju indeksa. Umjesto da se pretražuje cjelokupan sadržaj zapisa u jednoj ili više tablica kako bi se stiglo do željenih rezultata, optimizator upita bitno skraćuje postupak pretraživanja korištenjem indeksa kreiranih na tim istim tablicama. Uobičajeno je indekse dijeliti prema ulozi koju imaju na konkretnoj tablici na primarne indekse (ključeve), jedinstvene (unique) indekse ili “obične” indekse.
Ovaj put ćemo se malo detaljnije pozabaviti nešto drugačijim pogledom na indekse – njihovom internom strukturom. U literaturi se po tom pitanju često spominju pojmovi poput B-Tree, R-Tree, T-Tree ili fraktalnih indeksa, odnosno njihovih varijanti kao što su B+Tree, T+Tree i slično. Budući da su neke od navedenih vrsta indeksa posebno optimizirane za određene vrste podataka i konfiguracije hardvera/softvera, dobro je znati podržava li sustav za upravljanje bazom podataka odgovarajuću vrstu indeksa za većina potencijalnih podataka u bazi podataka. Ili je možda zbog optimalnih performansi bolje izabrati neko drugo rješenje.
B-TREE INDEKSI
U većini slučajeva kad se kod relacijskih sustava za upravljanje bazom podataka spominju indeksi, podrazumijevaju se upravo B-Tree indeksi ili neka od njihovih varijanti. B-Tree indeksi nastali su na temelju radova Rudolfa Bayera i Eduarda McCreighta iz 1972 godine. Iako im je naziv vrlo sličan binarnim stablima (binary tree) od njih se razlikuju u nekoliko važnih karakteristika. Navedeni stručnjaci su upravo radom na B-Tree indeksima pokušali ukloniti nedostatke binarnih stabala za praktično korištenje s velikim bazama podataka.
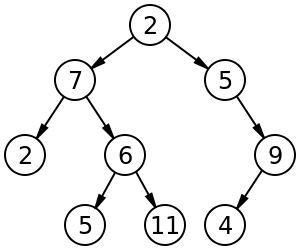
Slika 1. Primjer binarnog stabla
Kod binarnog stabla svaki čvor stabla (node) može pokazivati na najviše dva elementa (djecu ili potomke), dok sam čvor sadrži ključ po kojem se raspoređuje u binarnom stablu te samu vrijednost čvora (podatak). Binarno stablo predstavlja djelotvornu strukturu za pretraživanje podataka, ali pokazuje nedostatke u slučajevima kad podatke treba često mijenjati. U ekstremnim slučajevima nakon izmjene pojedinog podatka dolazi do reorganizacije cijelog stabla, što zbog pada performansi praktično nije iskoristivo u sustavima za upravljanje bazama podataka.
Kod B-Tree indeksa svaki čvor može sadržavati više vrijednosti ključeva te pokazivati prema većem broju elemenata (djece ili potomaka).
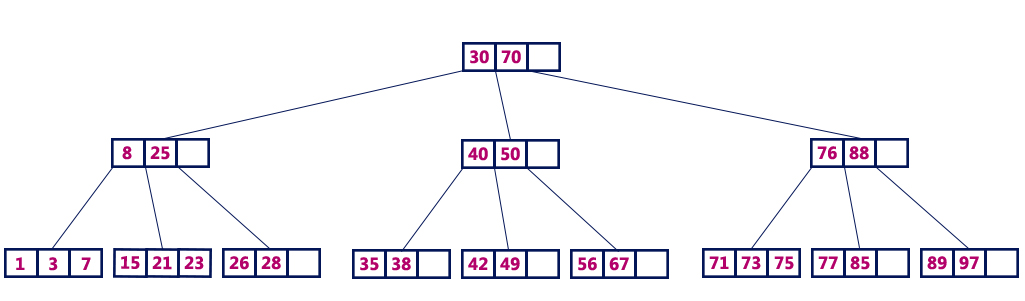
Slika 2. Primjer B-Tree stabla
Sa stanovišta pretraživanja podataka B-Tree indeksi su slični binarnom stablu, jedino umjesto dvije moguće vrijednosti elemenata niže razine, sada odluka o daljnjem pretraživanju treba donijeti obzirom na veći broj mogućih elemenata na koje pokazuje čvor. Algoritam za donošenje takve odluke je nešto složeniji nego kod binarnog stabla, ali upravo zbog mogućnosti postojanja većeg broja elemenata potomaka nego kod binarnog stabla (maksimalno dva), ukupno vrijeme pretraživanja je kraće, jer zahtijeva prolazak kroz manji broj razina do traženog rezultata.
Operacije dodavanja i brisanja podataka su također mnogo djelotvornije nego kod binarnog stabla. Veći broj potencijalno mogućih elemenata na nižoj razini stabla često omogućava dodavanje nove vrijednosti bez potrebe za detaljnijim prestrukturiranjem podataka u cijelom stablu. Kod operacije brisanja ostavljanje praznog mjesta u strukturi također smanjuje potrebu za promjenama u cijelom stablu.
B-Tree indeksi su posebno pogodni kod spremanja podataka na vanjske medije poput diskova (pristup kakav koristi većina baza podataka zbog razlike u kapacitetu vanjske i RAM memorije), koji su po brzini pristupa podacima znatno sporiji od RAM memorije. Pristup do određenog podatka na vanjskom mediju pomoću B-Tree indeksa bitno reducira broj čitanja zbog brzog prolaska od vrha do dna stabla u relativno malom broju koraka.
U slučaju da želite sami provjeriti kako na B-Tree indeksima izgleda izvođenje različitih operacija, možete isprobati slobodnu vizualizaciju njihovog rada dostupnu na web adresi: https://www.cs.usfca.edu/~galles/visualization/BTree.html
B+TREE INDEKSI
Predstavljaju posebno modificiranu verziju B-Tree indeksa kod kojih samo čvorovi na najnižoj razini (takozvani leaf nodes) sadrže stvarne podatke, dok svi ostali čvorovi više razine sadrže samo ključeve i veze prema drugim čvorovima u stablu. Takva organizacija stabla zahtijeva manje operacija nad stablom u slučaju ažuriranja podataka od osnovnog oblika B-Tree oblika indeksa, pa nije ni čudo da se koristi u velikom broju relacijskih sustava za upravljanje bazom podataka (SQL Server, MySQL InnoDB i drugi).
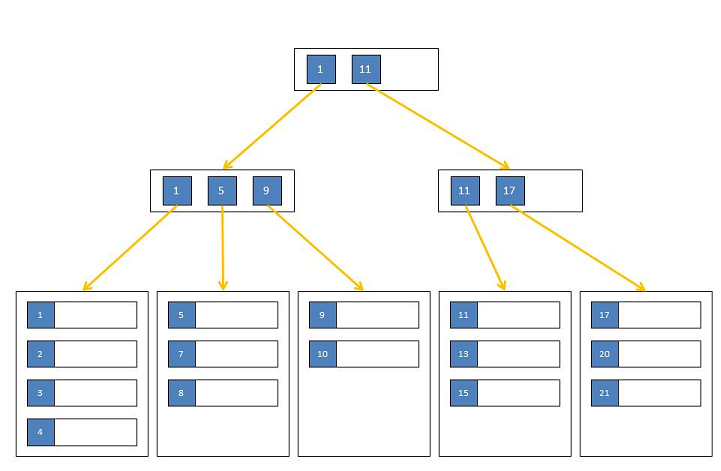
Slika 3. Primjer B+Tree stabla
T-TREE INDEKSI
Osnovna ideja kod razvoja T-Tree indeksa bila je u tome da konstantni razvoj hardvera vodi prema serverima s ogromnim količinama RAM memorije na kojima i najveće baze podataka mogu biti implementirane bez potrebe za korištenjem sporih vanjskih medija. Kod ove vrste indeksa čvorovi mogu sadržavati cijelo polje podataka. Zbog toga se operacije dodavanja i brisanja podataka često završavaju unutar takvog polja bez potrebe za stvaranjem novih čvorova ili uklanjanjem postojećih.
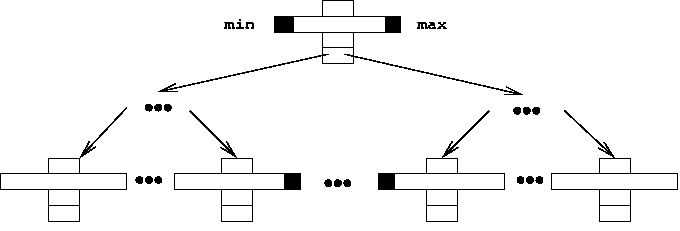
Slika 4. Primjer T-Tree stabla
Svaki čvor u stablu sadrži pokazivač prema roditeljskom čvoru te prema dva čvora potomka po čemu je sličan binarnom stablu. T-Tree indekse koriste sustavi za upravljanje bazama podataka čiji je cilj da svi podaci iz baze podataka budu smješteni u RAM memoriji računala (npr. Oracle TimesTen).
Problem s T-Tree indeksima može se pojaviti u nedovoljnoj iskorištenosti raspoloživih spremišta podataka u pojedinom čvoru stabla (ovisno o vrsti podataka) te sporijem prolasku kroz binarno organizirano stablo u odnosu na B-Tree indekse. Drugi nedostatak trebao bi biti kompenziran činjenicom kako se cijela struktura stabla nalazi u RAM memoriji s bitnom bržim radom od vanjskih medija.
Najnovija istraživanja na području usporedbe performansi B-Tree i T-Tree indeksa pokazala su da kod T-Tree indeksa performanse padaju ako operacije nad bazom podataka zahtijevaju veliki broj zaključavanja postojećih podataka u bazi, tako da gube prednost u brzini rada u odnosu na B-Tree indekse.
R-TREE INDEKSI
Kod određenih kategorija podataka ni jedna od prije navedenih vrsta indeksa ne predstavlja optimalan izbor. Najčešće je riječ o posebnim vrstama podataka kao što su geografski orijentirani podaci, gdje baza podataka treba često odgovarati na upite o prostornoj distribuciji objekata (na primjer popis svih muzeja na odstojanju 3 km od zadane referentne točke). U takvim slučajevima bolje rješenje predstavljaju R-Tree indeksi čiji je idejni začetnik bio Antonin Guttman 1984 godine.
Kod R-Tree indeksa izvodi se grupiranje bliskih objekata u najmanji mogući pravokutnik koji ih obuhvaća. Na razini najnižeg čvora takav pravokutnik je pojedinačni objekt, dok više razine predstavljaju grupiranje dvaju ili više bliskih objekata.
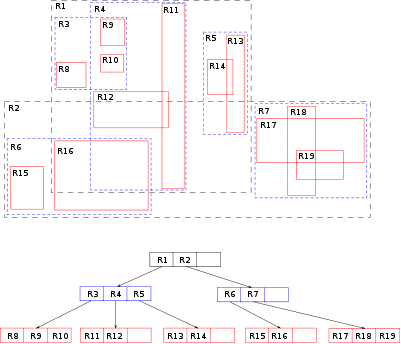
Slika 5. Primjer R-Tree indeksa
Najveći problem kod R-Tree indeksa je prilično slaba popunjenost stabla podacima te mogućnost pripreme teoretskih primjera gdje je korištenje R-Tree stabala vrlo problematično (što srećom nije slučaj za većinu primjera iz stvarnog svijeta). R-Tree indeksi najčešće se dodaju u standardne implementacije baza podataka kao posebni moduli ako se za tim ukaže potreba (npr. IBM Informix Spatial DataBlade Module).
FRAKTALNI INDEKSI
U osnovi po svojoj strukturi vrlo su slični B-Tree indeksima uz jednu vrlo bitnu nadogradnju. Čvorovi u stablu sadrže posebne međuspremnike za privremeno spremanje promjena u čvorovima u slučaju operacija dodavanja ili brisanja podataka. Ideja primjene takvih međuspremnika je u tome da se svaka mala promjena u stablu ne zapisuje trenutno na vanjski (spori) medij, nego da se odjednom zajedno zapisuje veći broj promjena skupljenih u međuspremnicima različitih čvorova. Na taj način se za većinu operacija promjene podataka u tablicama postiže znatno veća brzina rada nego što je to slučaj kod klasičnih B-Tree ili B+Tree indeksa.
Primjer implementacije fraktalnih indeksa je TokuDB – posebni Storage Engine modul za MySQL ili MariaDB.
ZAKLJUČAK
Osim nabrojenih vrsta indeksa odnosno pripadajućih stabala pretraživanja postoje njihove dodatne varijacije ili potpuno drugačije implementacije poput M-Tree, X-Tree, itd. Prethodni članak trebao bi poslužiti kao početna točka u njihovom proučavanju, to jest u uspoređivanju s opisanim vrstama indeksa.